Quick Anki
用 LLM 的力量,自动化你的词汇习得流程。
- 插件版本(推荐):quick-anki-addon
- 脚本版本(已归档):quick-anki
这是一个利用大语言模型(LLM)将原生文本整理并自动导入 Anki 的插件。
核心逻辑:Raw Text → LLM(提取/清洗)→ Check(查重)→ Import(制卡)。
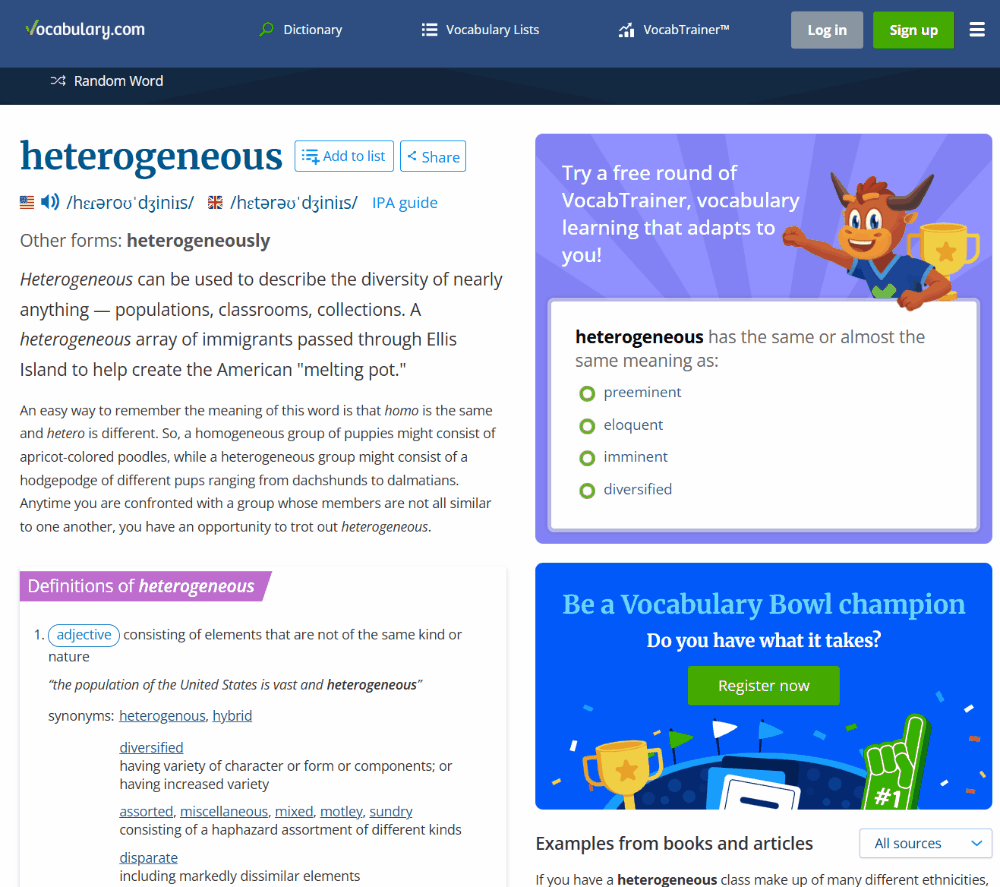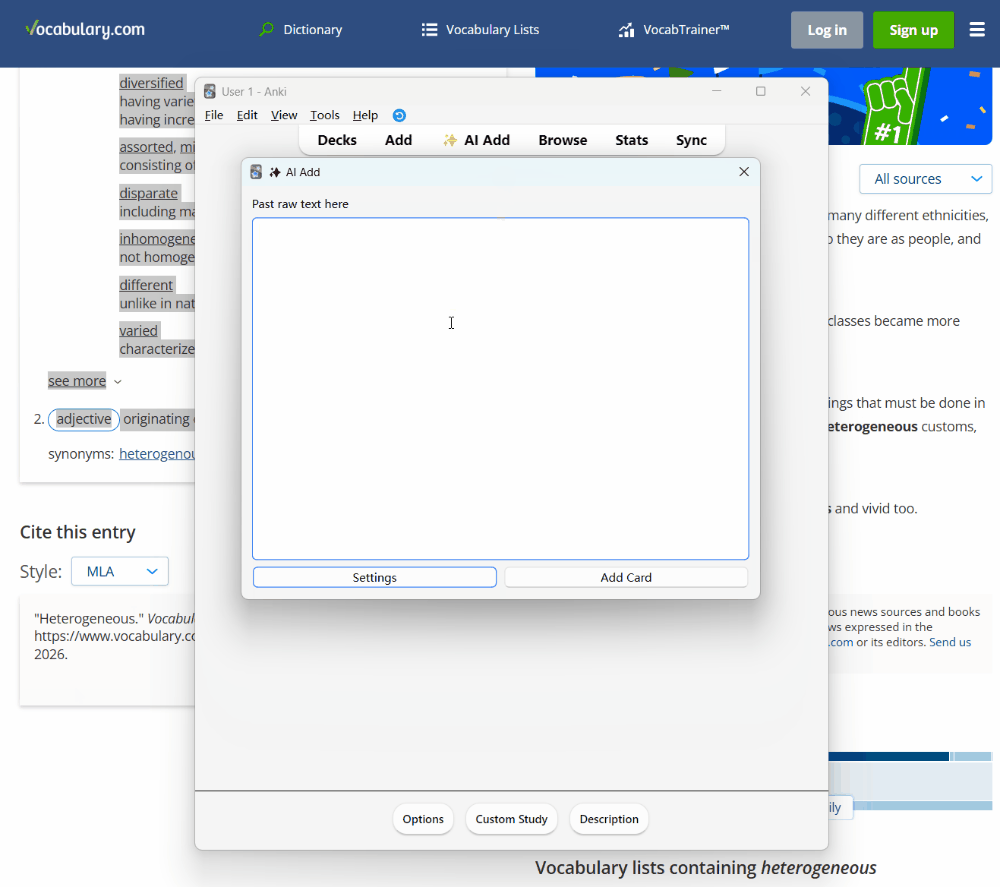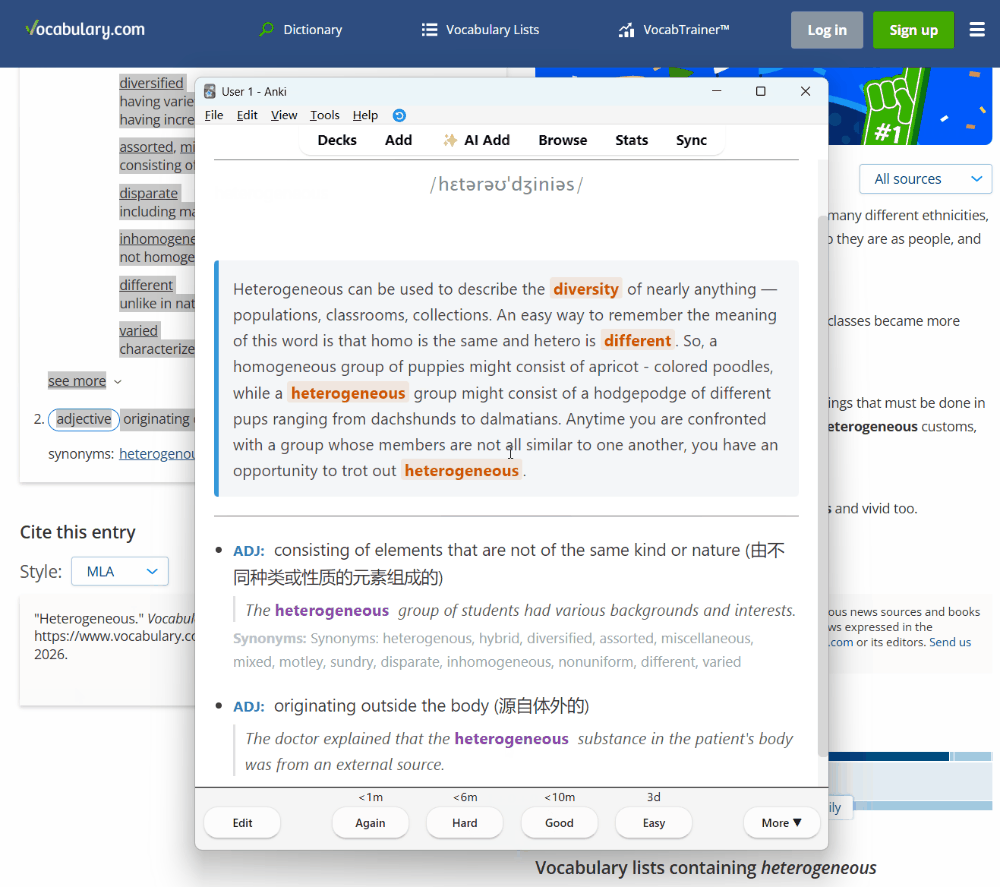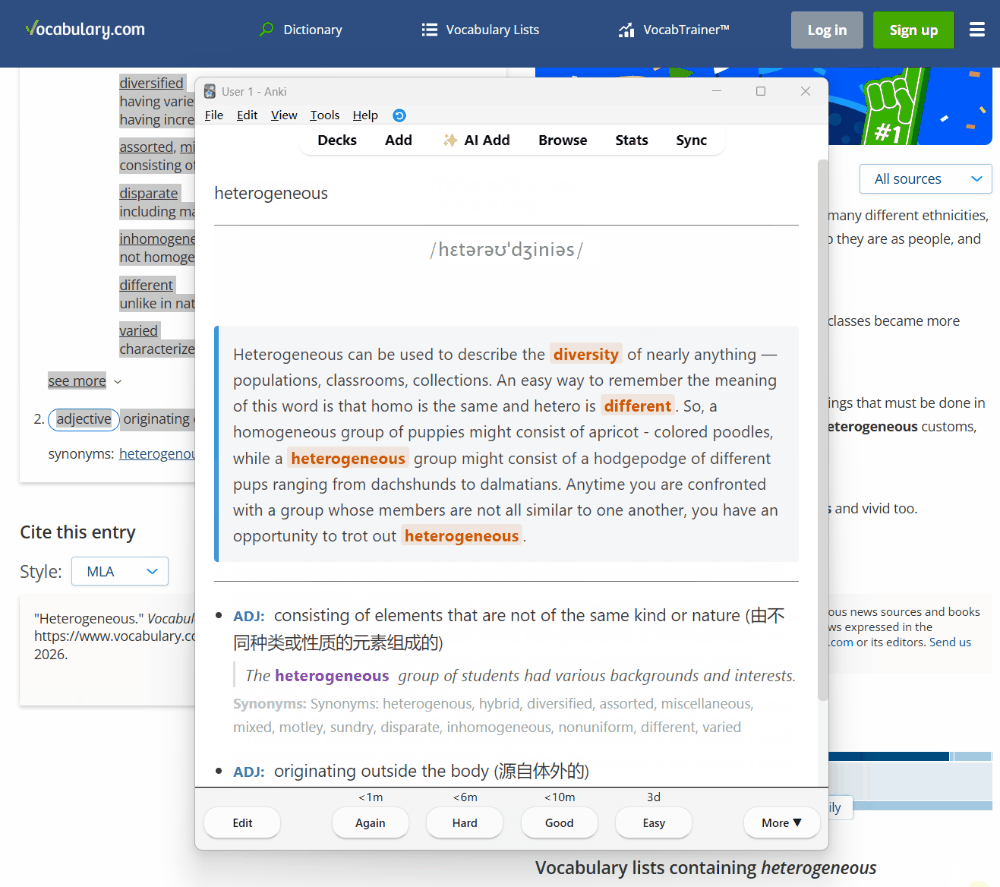 插件版本的流程演示:粘贴文本 → AI 解析 → 自动制卡
插件版本的流程演示:粘贴文本 → AI 解析 → 自动制卡
动机:帮助我学习单词
“Language is not a code to be decrypted, but a signal to be processed.”
在本项目(以及我的学习路径)中,我坚持一种非传统的单词记忆与语言习得方法。这种方法的核心在于拒绝”中英互译”,拥抱”英英定义”。
1. 为什么”中英词典”是低效的?
如果我们用机器学习(Machine Learning)的理论来审视语言,中文和英文本质上是两套完全独立的符号系统。这意味着:
- 英文单词 存在于
Vector Space A(向量空间 A) - 中文单词 存在于
Vector Space B(向量空间 B)
许多学习者试图通过中英词典建立直接映射(Mapping),即认为 Word_EN = Word_CN。但在高维语义空间中,这种映射往往是极其粗糙甚至错误的。
🌰 The “Apple” Paradox
我举个简单的例子,即使是简单的单词,其向量方向也不尽相同:
- 🇺🇸 Apple: 关联向量包括
Fruit,Adam & Eve (Sin/Temptation),New York (Big Apple),Technology,Pie. - 🇨🇳 苹果: 关联向量包括
水果,平安夜,红富士,脆/甜.
这两个词在物理实体上有重叠(Intersection),但在文化隐喻和语义联想上有着巨大的偏差。如果你只记住了 Apple = 苹果,你就丢失了 Apple 在英语语境下独有的所有高维特征。
2. 最佳实践:在英英词典中建立”印象”
学习单词的最好方式,不是寻找中文对应词,而是直接在英语的向量空间内建立坐标。
通过阅读英英词典(如 Vocabulary.com, Oxford, Merriam-Webster)的解释和例句,你是用已知英语单词去界定未知英语单词。这构建了一个封闭且自洽的英语神经网络,而不是依赖中文作为中介层。
这也是本项目为何着重提取 Blurb(语境解释)和英文 Definitions 的原因。
3. “Bug” 还是 “Feature”?
长期坚持这种方法,你可能会遇到一种现象:
“我知道这个词是什么感觉,但我一下子想不起来它的中文翻译。”
很多人认为这是缺陷(Bug),但我认为这是核心特性(Feature)。
- 传统模式(中介转译):
Concept→Chinese→English(高延迟,高损耗) - Native模式(直接映射):
Concept→English(低延迟,无损耗)
当你无法翻译,却能精准使用时,说明你已经像 Native Speaker 一样思考。你的大脑建立了一条直接通往英语概念的神经通路,这正是流利表达的生理基础。
4. 谁适合这种方法?
这种方法并不适合所有人,它有着明确的筛选门槛:
✅ 适合人群
- 面向”理解”的学习者:你的目标是看懂原版文档、无字幕听懂 YouTube 视频、或与国际开发者进行深度技术交流。
- 长期主义者:你不在乎短期内的单词量暴涨,更在乎构建纯正的语感。
- 开发者/逻辑思维者:习惯于理解底层逻辑,而非死记硬背表层符号的人。
- 已有一定基础者:你的词汇量足以支撑你阅读简单的英语释义(通常高中/CET-4以上水平即可启动)。
❌ 不适合人群
- 纯应试考生:如果你下周就要考四六级或考研,需要精准的中文释义来做翻译题,请使用中英词典高效刷题。
- 专业翻译人员:虽然翻译人员也需要英英思维,但他们必须额外训练”双语切换”能力,不能仅停留在”只懂不译”的阶段。
- 零基础初学者:如果连
Cat和Dog都需要查词,英英词典的递归查询会带来过高的认知负荷。
5. 这个项目如何帮助这个过程?
简化创建 Anki 记忆卡片的流程:
- 从 Vocabulary.com 或者其它词典中搜索结果
- 手动复制,贴到程序中
- 执行程序,自动解析杂乱的内容,创建卡片
从脚本到插件
这个项目经历了两个阶段的演进:
最初,我写了一个 Python 脚本 quick-anki,通过调用 AnkiConnect API 来实现自动制卡。它需要独立的 Python 环境和外部配置,使用门槛较高。
后来,我将其重构为 Anki 原生插件 quick-anki-addon,直接集成在 Anki 内部运行,无需配置 AnkiConnect 或外部 Python 环境。脚本版本已归档(archive),推荐使用插件版本。
功能特性
- 无缝集成:直接作为 Anki 插件运行,无需配置 AnkiConnect 或外部 Python 环境
- 智能清洗:利用 LLM(豆包/火山引擎等)从杂乱文本中提取单词、IPA 音标、语境解释(Blurb)和释义
- 智能查重:在插入卡片前,自动查询当前 Deck 中是否已包含该单词,避免重复制卡
- 可视化日志:处理过程中实时显示日志,方便排查问题
安装与配置
前置要求
- Anki Desktop:Anki 2.1+ 版本
- API Key:拥有火山引擎(豆包)或其他兼容 OpenAI SDK 格式的 API Key
安装插件
将插件文件夹 quickanki 放入 Anki 的插件文件夹中(通常位于 AppData/Roaming/Anki2/addons21/),重启 Anki。
配置 API
- 重启 Anki 后,在顶部工具栏点击 ”✨ AI Add” 按钮
- 在弹出的窗口中点击 “Settings”
- 填入 LLM 配置信息:
Model ID:模型名称(如doubao-1-5-pro-32k-250115)Base URL:API 基础地址(如https://ark.cn-beijing.volces.com/api/v3)API Key:你的 API 密钥Deck Name:目标牌组名称(如Vocabulary)
使用方法
- 点击工具栏上的 ”✨ AI Add” 按钮
- 在文本框中粘贴你想要学习的单词或原生文本(例如来自 Vocabulary.com 的段落)
- 点击 “Add Card”
- 插件会自动调用 LLM 进行处理,检查重复,并将生成的卡片添加到指定的牌组中
添加 CSS
为了让卡片背面更加美观,请在 Anki 的 “浏览” → “卡片…” → “样式” 中添加以下 CSS(也可以参考仓库中的 basic.css 文件):
/* --- 基础卡片设置 --- */
.card {
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif;
font-size: 18px;
text-align: left;
color: #333;
background-color: white;
line-height: 1.6;
}
/* --- 单词本体 (Front) --- */
.card-front {
font-size: 36px;
font-weight: bold;
text-align: center;
color: #2c3e50;
margin-bottom: 10px;
}
/* --- 音标 (IPA) --- */
.ipa {
font-family: "Lucida Sans Unicode", "Arial Unicode MS", sans-serif;
font-size: 1.1em;
color: #7f8c8d;
text-align: center;
margin-bottom: 20px;
margin-top: -10px;
}
/* --- 语境解释 (Blurb) --- */
.blurb {
background-color: #f4f6f8;
border-left: 5px solid #3498db;
padding: 15px;
margin: 15px 0;
border-radius: 4px;
color: #444;
font-size: 0.95em;
}
.blurb b {
color: #d35400;
background-color: rgba(211, 84, 0, 0.1);
padding: 0 4px;
border-radius: 3px;
font-weight: 700;
}
/* --- 分割线 --- */
hr {
border: 0;
height: 1px;
background-image: linear-gradient(to right, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.15), rgba(0, 0, 0, 0));
margin: 20px 0;
}
/* --- 释义列表 --- */
ul {
padding-left: 20px;
margin: 0;
}
li {
margin-bottom: 20px;
}
/* --- 词性 (adj/noun) --- */
li b {
color: #2980b9;
font-weight: bold;
text-transform: uppercase;
font-size: 0.85em;
margin-right: 5px;
}
/* --- 例句样式 (Example) --- */
.example {
display: block;
margin-top: 6px;
margin-bottom: 4px;
padding-left: 10px;
border-left: 3px solid #e0e0e0;
color: #555;
font-size: 0.95em;
font-style: italic;
}
.example b {
color: #8e44ad;
font-weight: bold;
font-style: normal;
background: none;
text-transform: none;
font-size: 1em;
}
/* --- 同义词 (Synonyms) --- */
li i {
display: block;
font-size: 0.85em;
color: #95a5a6;
margin-top: 4px;
font-style: normal;
}
li i::before {
content: "Synonyms: ";
font-weight: bold;
color: #bdc3c7;
}
/* === 夜间模式适配 (Dark Mode) === */
.nightMode .card {
background-color: #2f2f31;
color: #dcdcdc;
}
.nightMode .card-front {
color: #ffffff;
}
.nightMode .ipa {
color: #aaaaaa;
}
.nightMode .blurb {
background-color: #3a3a3a;
border-left-color: #5ea8ff;
color: #e0e0e0;
}
.nightMode .blurb b {
color: #ffaa80;
background-color: rgba(255, 170, 128, 0.15);
}
.nightMode hr {
background-image: linear-gradient(to right, rgba(255, 255, 255, 0), rgba(255, 255, 255, 0.2), rgba(255, 255, 255, 0));
}
.nightMode li b {
color: #6dd5ed;
}
.nightMode .example {
color: #b0b0b0;
border-left-color: #555;
}
.nightMode .example b {
color: #c77dff;
}
.nightMode li i {
color: #888;
}常见问题
-
LLM 请求失败 / 网络错误
- 请检查你的 API Key 和 Base URL 是否正确
- 如果在中国大陆使用 OpenAI 等服务,可能需要检查网络环境
-
LLM 返回格式错误
- 插件内置了 JSON 提取器,但 LLM 偶尔可能返回不符合预期的格式
- 如果频繁报错,请检查日志窗口中的 “LLM 原始返回”,可能需要微调
main.py中的 Prompt